




אֱלִיעֶזֶר בּוֹט יְהוּדָה,
זֶהוּ רוֹבּוֹט מְבַדֵּחַ,
מִלִּים מִלִּים, מִלִּים מִלִּים,
הוּא בּוֹדֶה מִמְּעַבְּדוֹ הַקּוֹדֵחַ!
1. הקדמה
השאלה 'האם מחשב יכול להיות יצירתי?' היא שאלה מורכבת שעומדת בבסיסו של תחום מחקר מתפתח הנקרא יצירתיות חישובית.
יצירתיות חישובית מחברת בינה מלאכותית, פסיכולוגיה קוגניטיבית, פילוסופיה ואומנות. מטרת המחקר בתחום היא להבין טוב יותר יצירתיות אנושית, ובד בבד לבנות מערכות המסוגלות ליצירתיות ברמה אנושית או לתמוך בתהליכי יצירה אנושיים.
עד כה נעשו לא מעט ניסיונות לבנות מערכות יצירתיות, בהן כאלו המייצרות שירה, סיפורים, מלודיות, מתכונים, ציורים ועוד. בהמשך לעבודות אלו, בעבודתנו הנוכחית ניסינו לבנות מערכת המייצרת באופן אוטומטי חלופות עבריות למילים לועזיות. הראינו כי פלטי המערכת שומרים על חוקי לשון בסיסיים וכי באפשרותה להיות לעזר למומחי שפה ולספק להם השראה.
כמחווה למחיה השפה העברית הענקנו למערכת את השם אֱלִיעֶזֶר בּוֹט יְהוּדָה.
הקלט למערכת הוא מילה באנגלית (שם עצם), והפלט הוא חלופות עבריות למילה.
לדוגמה, עבור מילת הקלט palette (פָּלֵטָה בלעז, כלי המשמש ציירים לארגון וערבוב צבעים), הפלט של האלגוריתם נתן כמה חלופות: מַצְבֵּעָה, עַרְבֶּלֶת, קַשֶּׁתֶת, לוּחַ צֶבַע, עִרְבּוּלוּחַ ועוד. לשם השוואה החלופה העברית הרשמית למילה זו היא פְּתֵכָה (מהשורש פ-ת-ך ששימש בלשון חז"ל במשמעות עירוב).
דוגמה נוספת: עבור מילת הקלט debate (דיבייט בלועזית) הפלט נתן את החלופות שִׂיחוּחַ, פִּלְמוּס, נְצִיחָה, נְמִיקָה, תגר שיחה, קרב דיון ועוד. החלופה העברית הרשמית היא מַעֲמָת.
2. תיאור המערכת
במאמרו של קית סויר "Explaining Creativity: The Science of Human Innovation", הוא מגדיר שלבים בתהליך היצירה האנושית. השלבים הראשונים הם הגדרת הבעיה וספיגת ידע ממקורות חיצוניים. ידע זה יסייע לנו להבין מה כבר נעשה בעבר, ייתן לנו השראה לרעיונות חדשים ויעזור לנו לשפוט חדשנות של רעיונות מוצעים. בהמשך מגיעים השלבים של ייצור רעיונות (שלב מפתח ביצירה האנושית) וסינון הרעיונות המוצלחים ביותר.
בעבודתנו עקבנו גם אנחנו אחר הפרדיגמה הזאת – יש לנו שלב של ייצור הצעות לחלופות (שמות עצם) ושלב של סינון החלופות המוצלחות יותר.
את תהליך ייצור החלופות חילקנו לשתי תתי־משימות:
- ייצור שמות עצם חדשים על בסיס שילוב של שורש ומשקל.
- ייצור שמות עצם על בסיס צירוף של מילים קיימות והלחמי בסיסים.
נדגיש כי מרב המאמצים בבניית המערכת התמקדו בתת־המשימה הראשונה – יצירת שמות עצם חדשים על בסיס שילוב של שורש ומשקל (דרך התצורה המועדפת בשפה העברית). מכיוון שיש מושגים בשפה שכדי לתאר אותם זקוקים למספר מילים, המערכת תומכת גם ביצירת חלופות לשמות עצם שהן צירוף של מילים קיימות והלחמי בסיסים. נפנה כעת לתיאור מימוש תת־המשימה הראשונה, שהיא המעניינת יותר מבחינה רעיונית וטכנית, ובחלק של סיכום תיאור המערכת (סעיף 2.5) נספק גם פרטים כלליים על אודות אופן המימוש של תת־המשימה השנייה.
כדי לייצר הרבה חלופות בעברית שהן שילוב של שורש ומשקל עלינו למצוא שורשים רלוונטיים (שמרמזים על משמעות המילה) ומשקלים רלוונטיים (שיכולים לרמז על הקטגוריה של המילה, כגון קַטֶּלֶת למחלות).
משום שהמקורות בעברית ברשת יחסית דלים, פנינו לניצול המקורות המאוד מקיפים שיש באנגלית ברשת.
2.1. חילוץ שורשים

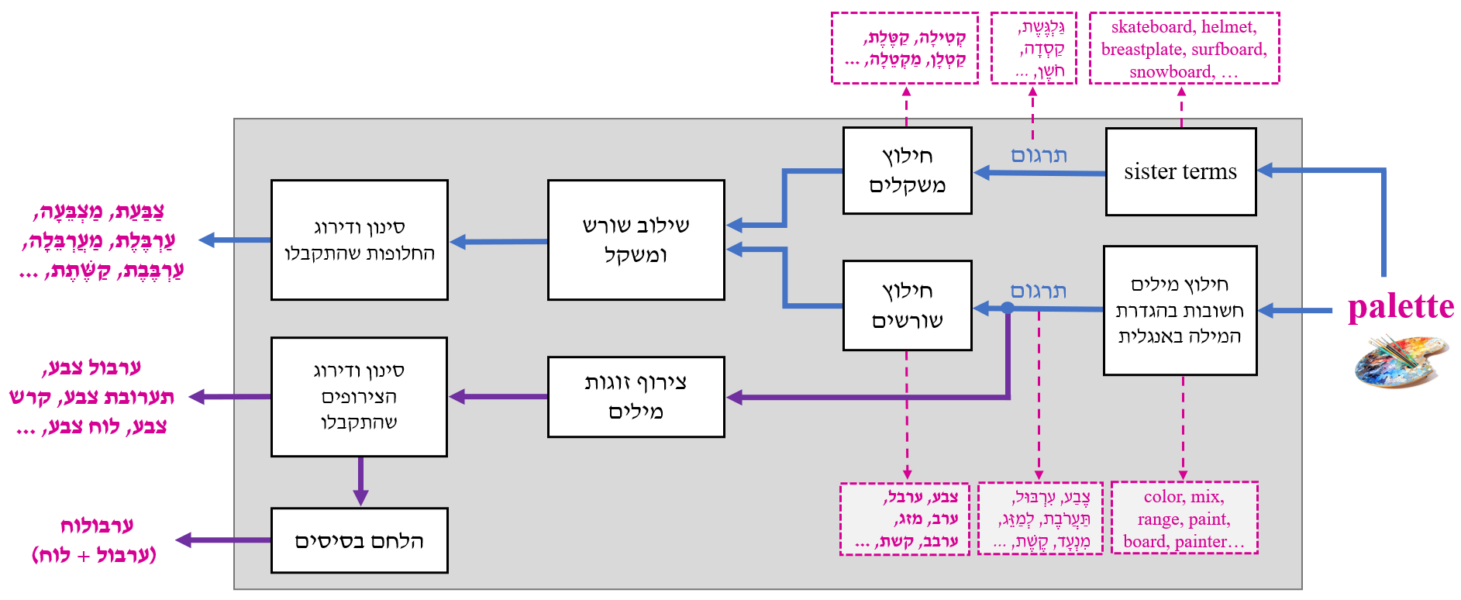
כדי לחלץ שורשים אספנו מילונים רבים באנגלית וייצרנו "מסמך" עבור כל אחד מהמושגים שהופיעו במילונים אלה. בכל מסמך איגדנו את כל ההגדרות שהופיעו במילונים עבור המושג (ראו המחשה בתמונה של מסמך עבור המושג palette המאגד הגדרות שונות למושג זה).
בהינתן מסמכי המושגים פנינו למציאת המילים החשובות המופיעות בהגדרות של כל מושג באנגלית. כדי לעשות זאת השתמשנו ב־tf-idf. מדד tf-idf הוא מדד מספרי המבוסס על נוסחה מתמטית שהוגדר כדי לחזות חשיבות של מילים מסוימות במקבצי מסמכים. לדוגמה, במסמך שמאגד את כל ההגדרות של המושג palette, לפי מדד זה המילה color תקבל ציון גבוה יחסית משום שהיא חוזרת מספר גדול של פעמים במסמך וייחודית למושג palette. לעומתה המילה the תקבל ציון נמוך – אומנם ניתן לצפות לחזרות רבות שלה במסמך, אך היא איננה ייחודית למושג הספציפי שהמסמך מייצג והיא מופיעה רבות גם במסמכים שמייצגים מושגים אחרים.
לאחר שקיבצנו את המילים החשובות עבור מושג ספציפי, פנינו לתרגמן לעברית באמצעות מילונים חופשיים (אנגלית–עברית) שנמצאים ברשת וחילצנו בעזרת מקורות חופשיים את השורשים של מילים אלו. בשורשים אלו השתמשנו לבניית המילים החדשות שהן שילוב של שורש ומשקל.
חשוב לציין שלו המקורות שהיו בידינו (תרגום אנגלית–עברית וחילוץ שורשים) היו מקיפים יותר, ניתן היה לצפות לשיפור ניכר של המערכת בחילוץ השורשים המעניינים עבור כל מושג. לדוגמה, עבור המילה allergy החלופה שהציעה האקדמיה היא רַגֶּשֶׁת – כשילוב של משקל המחלות קַטֶּלֶת והשורש ר-ג-ש, המבטא רגישות יתר. כשהאלגוריתם שלנו חיפש את המילים החשובות בהגדרת המושג allergy, אחת המילים שדורגה גבוה במיוחד הייתה המילה hypersensitivity שניתן לתרגמה לעברית כ"רגישות יתר". עם זאת כיוון שלא היה תרגום למילה במקורות התרגום שמצאנו השורש ר-ג-ש הוחמץ.
2.2. חילוץ משקלים
בהרבה מהמקרים משקל קובע את משמעותה של המילה. למשל, המשקלים מַקְטֵל, מַקְטֵלָה ומִקְטֶלֶת מציינים לרוב מכשיר או כלי, והמשקל קַטֶּלֶת מציין בדרך כלל מחלות אך גם כלים ומכשירים וקבוצות ואוספים.
כדי לחלץ תבניות משקלים אפשריות למושג השתמשנו במדרג של מושגים באנגלית שנקרא WordNet הפתוח לכול.
במדרג זה אם נבחן לדוגמה את המושג carpenter (נגר), עלייה בשלב אחד במדרג תיתן לנו את המושג wood worker (נגר משתייך לקבוצת עובדי העץ).
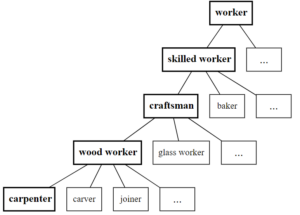
עליית שלב נוסף במדרג תביא אותנו ל־craftsman (עובדי העץ משתייכים לקבוצת בעלי המלאכה). עלייה נוספת תביא אותנו ל־skilled worker (קבוצת העובדים בעלי המיומנויות) ואז למושג הכללי של worker (קבוצת העובדים).
ניתן גם לרדת במדרג באותו האופן ולבדוק מה הם המושגים הספציפיים שנמצאים מתחת למושג מסוים. לדוגמה, תחת wood worker (קבוצת עובדי העץ) ניתן למצוא בין היתר גם את המושג carver (אדם המגלף בעץ).
כך אנו יכולים להסתכל על ה"אחים" של המושג carpenter, כלומר המושגים שחולקים איתו את האב הישיר wood worker (דוגמת המושג carver), וגם על "בני הדודים" של המושג (המושגים שחולקים איתו את הסב craftsman) וכן הלאה. כל המושגים הללו נמצאים במדרג תחת המושג worker. לכן סביר שיהיו בעלי מקצוע, ואם נתרגם אותם לעברית נצפה למילים שמשקלים של בעלי מקצוע רווחים בהן (כגון קַטָּל, קַטְלָן וקַטַּאי).
לסיכום, כדי לחלץ משקלים אפשריים עבור מושג, שלפנו את המושגים שיש להם מושג אב משותף עם מושג המקור שלנו במדרג של WordNet. את המושגים האלה תרגמנו לעברית וחילצנו מהם משקלים (אם היה להם תרגום וגם משקל במקורותינו). המשקלים הנפוצים ביותר שנמצאו אלו המשקלים שבהם השתמשנו לבניית החלופות החדשות.
2.3. שילוב שורש ומשקל
כעת, לאחר שחילצנו שורשים ומשקלים, נרצה לשלבם לכדי חלופות חדשות.
הדרך הנאיבית לשלב שורש ומשקל תהיה להציב את אותיות השורש במקום האותיות ק-ט-ל בתבנית שמייצגת את המשקל. לדוגמה, תוצאת הצבת השורש ז-מ-ר במשקל תִּקְטֹלֶת תהיה המילה תִּזְמֹרֶת.
אולם, מתברר כי כשני שלישים מן השורשים בעברית הם שורשים בגזרה מיוחדת ודורשים התאמות נוספות לאחר ההצבה הנאיבית. לדוגמה, תוצאת ההצבה הנאיבית של השורש ר-פ-א במשקל תַּקְטֵלָה היא תַּרְפֵּאָה, אך משום שמדובר בשורש מיוחד (מגזרת ל"א – שורשים המסתיימים באות א'), לאחר התאמות לשוניות המילה המתקבלת מהשורש והמשקל המדוברים היא בעצם המילה תְּרוּפָה.
לאחר נבירה בספרות הבנו שישנם חוקים לשוניים ויוצאי דופן רבים, מה שהביא אותנו לממש קופסה שמקבלת כקלט שורש ומשקל ומחזירה כפלט את השילוב של אלו (ראו איור מצורף). במימוש הקופסה יש שלב שמשלב באופן נאיבי את השורש והמשקל ושילוב זה ניתן למודל מאומן (character-based attentional seq2seq model) שתפקידו לבצע באופן אוטומטי ובצורה סבירה את השינויים הלשוניים הנדרשים לאחר הצבה נאיבית.
כדי לאמן את המודל אספנו את כל המילים שאנו יודעים את השורש ואת המשקל שלהן (מהמקורות החופשיים שהיו ברשותנו), ועבור כל מילה ייצרנו את השילוב הנאיבי שמתקבל מהצבת השורש שלה במשקל שלה (עבור המילה תְּרוּפָה השילוב הנאיבי הזה הוא תַּרְפֵּאָה כפי שהדגמנו למעלה). לאלגוריתם לאימון המודל סיפקנו את השילוב הנאיבי ומידע ספציפי על הגזרות שאליהן משתייך השורש; וכמו כן את השילוב הסופי הרצוי לאחר ביצוע השינויים הלשוניים (המילה עצמה). על האלגוריתם היה ללמוד בעצמו (על סמך תופעות נשנות שמצא בזוגות שניתנו לו) את החוקים הלשוניים הנדרשים לביצוע שינויים בתוצר של ההצבה הנאיבית. בתום תהליך האימון היה בידינו מודל שמקבל כקלט שילוב נאיבי של שורש ומשקל ומידע לגבי הגזרות שאליו משתייך השורש ופולט את המילה לאחר ביצוע השינויים הלשוניים הנדרשים בה.
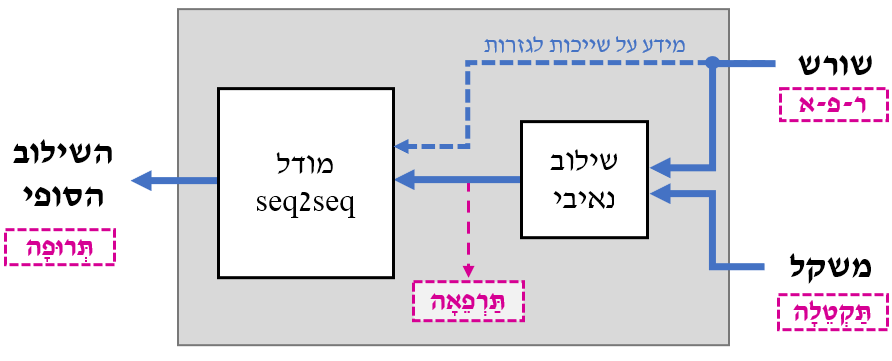
מובן שהמודל אינו מחליף לשונאי, אך הוא פעל בצורה סבירה בהחלט והצליח ללמוד לבד חוקי לשון מוכרים, לדוגמה שאותיות בג"ד כפ"ת בראש מילה ולאחר שווא נח מקבלות דגש קל, שחטף מחליף שווא בעיצור גרוני ועוד.
2.4. סינון ודירוג של החלופות שהתקבלו
לפני שנמשיך נסכם את הפעולות שביצענו עד כה. התחלנו מאיתור שורשים ומשקלים בעלי עניין לתיאור המושג שעבורו אנחנו מחפשים חלופות חדשות. לאחר מכן עבור כל זוג של שורש ומשקל שמצאנו, הצבנו את השורש בתוך המשקל באופן נאיבי, ואת התוצר מהצבה זו הכנסנו לתוך מודל שמבצע שינויים לשוניים בהצבה הנאיבית אם נדרש. בידינו חלופות. כעת אנו פונים לסנן מהן את החלופות הפחות סבירות ולדרג את אלה שנותרו (הדירוג יקבע את סדר הצגת החלופות למשתמש).
סינון חלופות: תחילה אנו מסננים חלופות שכבר קיימות בעברית (או לפחות במקורות החינמיים שבידינו). לאחר מכן אנו פונים לסנן חלופות שלא סביר שיהוו מילה בעברית. שלב הסינון האחרון נדרש משום שהאלגוריתם לשילוב שורש ומשקל אינו מושלם ויכול לספק גם תוצרים שאינם מתאימים לשפה.
כדי לסנן מילים שלא סביר שהן מילה בעברית באופן אוטומטי, אנו צריכים שלמערכת שלנו תהיה רמת היכרות והבנה בסיסית של השפה העברית. לשם כך אימנו מודל נוסף הנקרא בשפה המקצועית מודל שפה. מודל זה קרא הרבה טקסטים מנוקדים בעברית שניתן למצוא ברשת (פרויקט בן־יהודה) ותפקידו היה ללמוד את שכיחות רצפי התווים בשפה (אותיות וניקוד) מטקסטים אלו. בתום תהליך הלמידה המודל אמור בהינתן מילה לדעת לתת לה ציון – ציון גבוה מעיד על התאמה גבוהה של המילה לשפה וציון נמוך מעיד על חוסר התאמה. לדוגמה, המילה "חֲמִירָה" קיבלה ציון גבוה ממודל השפה שלנו, ואילו המילים "מֶשֶׁ", "מִשְׁוֹן" ו"גְּיִיבָה" קיבלו ציון נמוך מאוד שמעיד על חוסר התאמתן לשפה.
דירוג חלופות: אנחנו מדרגים גבוה יותר את החלופות ששורשיהן הגיעו מהמילים עם ניקוד ה־tf-idf הגבוה יותר (שמעיד כזכור על חשיבות המילה בהגדרה). באופן הזה חלופות עבור המילה palette (פָּלֵטָה) שהשורש שלהן הוא צ-ב-ע ידורגו גבוה יותר ממילים שהשורש שלהן הוא ק-ר-ש משום שהמילים שקשורות לשורש צ-ב-ע נמצאו חשובות יותר מהמילים הקשורות לשורש ק-ר-ש בהגדרה של המילה באנגלית.
2.5. סיכום תיאור המערכת
הסכֵמה הבאה מאגדת את כל שלבי מימוש המערכת. מימין מילת קלט לדוגמה (palette) ומשמאל החלופות שהתקבלו עבורה. בכחול מסומן תהליך ייצור חלופות על בסיס שילוב של שורש ומשקל כפי שתואר לעיל. בסגול מסומן תהליך ייצור חלופות על בסיס צירוף מילים קיימות והלחמי בסיסים. בתהליך זה אנו משתמשים במילים החשובות שחולצו מהגדרת מילת הקלט ותורגמו לעברית. ממילים אלו אנו מייצרים את כל הצירופים האפשריים ומהם אנו מסננים זוגות מילים שלא מתאימות מבחינת מין או מספר או שהן מילים נרדפות. בתום תהליך זה בידינו חלופות שהן צירופי מילים. לסיום, עבור צירוף שהמילים המרכיבות אותו חולקות הגה משותף אנו מייצרים גם הלחם (לדוגמה, "עִרְבּוּלוּחַ" עבור הצירוף "עִרְבּוּל לוּחַ").
 3. ניסויים
3. ניסויים
כעת, כשבידינו מערכת ליצירת חלופות בעברית, ברצוננו לבחון שתי שאלות: האם המערכת שלנו בכלל מסוגלת לייצר חלופות שהן מוצלחות בהשוואה לחלופות אנושיות? והאם תוצרי המערכת יכולים לשמש מקור השראה ולשפר את תהליך היצירה האנושית?
לשם כך עברנו על פרוטוקולי ישיבות האקדמיה מהעשורים האחרונים ואספנו 20 מילים לועזיות שהיו להן מספר חלופות שהועלו להצבעה והן פחות מוכרות בציבור. עבור מילים לועזיות אלו ייצרנו חלופות באמצעות המערכת שלנו. יתר על כן, נתנו לארבעה לא־מומחים להציע חלופות משל עצמם לפני חשיפה לתוצרי המערכת ולאחריה.
בשלב זה עבור 20 המילים הלועזיות הנבחרות יש בידינו חלופות המערכת, הצעות מומחי האקדמיה והצעות הלא־מומחים לפני החשיפה לחלופות המערכת ואחריה. שימו לב שמעניין אותנו להעריך גם את איכות החלופות של המערכת (מערכת ללא בני אדם) וגם את השיפור של בני אדם שקיבלו השראה מהמערכת (בני אדם + מערכת).
מספר חלופות המערכת וההצעות של הלא־מומחים היה גדול בהרבה ממספר ההצעות של מומחי האקדמיה. כדי לצמצם מספר זה בחרנו לחקות את תהליך סינון החלופות של האקדמיה והעלינו אותן להצבעה בוועדה של שלושה מתנדבים חובבי השפה.
לאחר סינון ההצעות של הקבוצות השונות, הרצנו סקר מקוון (אונליין) שבו 177 משתתפים דירגו את החלופות בשלושה מדדים: (1) מידת התאמת החלופה למילת המקור; (2) מידת החיבה לחלופה; (3) מידת יצירתיות החלופה.
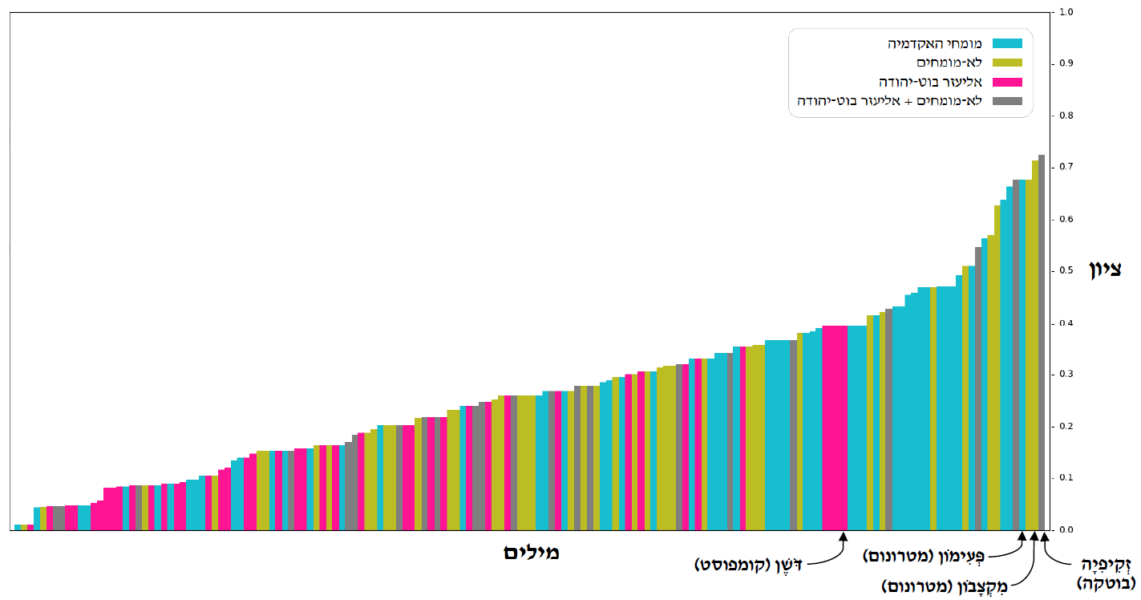
לכל אחת מההצעות חישבנו ציון שמשלב את הדירוגים שלהן בשלושת המדדים. בגרף למטה כל עמודה מציינת הצעה לחלופה, גובהה של העמודה הוא הציון המשולב שקיבלה, וצבעה מעיד על הקבוצה שממנה הגיעה (מערכת, מומחים, לא־מומחים, לא־מומחים לאחר חשיפה לתוצרי המערכת).
איכות תוצרי המערכת בהשוואה לתוצרים אנושיים
ניתן לראות שהצעות המומחים הן חלק גדול מחלקו הימני של הגרף, שמייצג את החלופות עם הציונים הגבוהים ביותר. עם זאת הצעות המערכת משולבות על פני הגרף וחלקן אף עוברות בציוניהן לא מעט מההצעות האנושיות.
בין החלופות שהציעה המערכת שלנו הופיעה החלופה "בָּקְבִּיק" עבור המילה הלועזית אמפולה. לשם השוואה החלופה הרשמית של האקדמיה היא בַּקְבּוּקִית. הופיעה גם החלופה דֹּשֶׁן עבור קומפוסט (החלופה של האקדמיה: דְּשֹׁנֶת) ו־גְּבִיעוּגָה לקפקייק (החלופה של האקדמיה: עוּגוֹנִית). באופן מפתיע חלק מהחלופות שהציעה המערכת היו זהות לחלופות שהועלו להצבעה בישיבות האקדמיה כדוגמת פִּלְמוּס עבור המילה דיבייט ותַקָּן כחלופה להנדימן.
דוגמה מעניינת לחלופה שסיפקה המערכת היא סָכָּל־זֵעָה עבור דאודורנט (החלופה של האקדמיה: תַּכְשִׁיר אַל־רֵיחַ). המילה מתאימה במשמעות אך הציבור כנראה לא היה מאמץ אותה בגלל הקונוטציות השליליות שלה. זו המחשה נוספת למורכבות הבעיה, שכן הבנת קונוטציות היא אומנם משימה פשוטה לאדם, אך היא אתגר מהותי עבור מחשב.
תרומת המערכת לשיפור תהליך היצירה האנושית
עבור כל מילה לועזית השווינו את ההצעה הטובה ביותר של הלא־מומחים לפני החשיפה לתוצרי המערכת להצעה הטובה ביותר שלהם לפניה ולאחריה. נוכחנו שעבור 20% מהמילים, החשיפה לתוצרי המערכת גרמה ליצירת חלופה מתאימה ואהובה יותר, ועבור 35% מהמילים החשיפה גרמה ליצירת חלופה יצירתית יותר.
החשיפה לתוצרי המערכת גם צמצמה את הפער בין הצעות הלא־מומחים להצעות המומחים. עבור 45% מהמילים החלופה הטובה ביותר של הלא־מומחים, לאחר החשיפה לתוצרי המערכת, עקפה את זו של המומחים בציון המשולב (בהשוואה ל־35% בלבד לפני כן). כמו כן עבור 70% מהמילים החלופה הטובה ביותר של הלא־מומחים לאחר החשיפה לתוצרי המערכת עקפה את זו של המומחים ביצירתיות (בהשוואה ל־55% לפני כן).
בין הצעות הלא־מומחים לאחר החשיפה לתוצרי המערכת היו החלופות זְקִיפִיָה עבור בּוּטְקֶה (החלופה הרשמית של האקדמיה: שׁוֹמֵרָה), חֲלִיפוֹן עבור וריאציה (האקדמיה: הֶגְוֵן) וסְפַרְפַר עבור פריפריה (אין חלופה רשמית של האקדמיה). שלוש החלופות הללו קיבלו אהדה רבה במיוחד ממשתתפי הניסוי ועקפו את הצעות המומחים בכל המדדים.
לקהל הרחב
לפניכם רשימת מונחים בלועזית – התדעו לזהות מהי החלופה העברית שקבעה האקדמיה ללשון העברית ומהי המילה שהמציא אליעזר בוט יהודה?
| (1) זיגזג (zigzag) | א – סִכְסָךְ | ב – שֶׁנָן |
| (2) קוקטייל (cocktail) | א – תַּגְמִיא | ב – מִמְזָג |
| (3) בלנדר (blender) | א – רָצָץ | ב – מַמְחֶה |
| (4) קונספירציה (conspiracy) | א – הַזְמָמָה | ב – קֶשֶׁר |
| (5) בלק אאוט (blackout) | א – חִשָּׁכוֹן | ב – מַשְׁחֵר |
| (6) ריצ'רץ' (zipper) | א – פֶּרֶף | ב – רוֹכְסָן |
| (7) אנטנה (antenna) | א – מְשׁוֹשָׁה | ב – מְקַשֵּׁר |
| (8) טיזר (teaser) | א – מַקְנֵט | ב – גַּרְיָן |
| (9) טורבן (turban) | א – רָאִישׁ | ב – צָנִיף |
| (10) מיגרנה (migraine) | א – צִלְחָה | ב – תַּחֲמִיר |
| (11) אנלוגיה (analogy) | א – הֶקֵּשׁ | ב – מַקְבָּל |
| (12) אנטידוט (antidote) | א – סוֹתְרָן | ב – נָטְרָל |
התשובות (החלופות הרשמיות של האקדמיה):
(1) א; (2) ב; (3) ב; (4) ב; (5) א; (6) ב; (7) א; (8) ב; (9) ב; (10) א; (11) א; (12) א.